
Cómo registro mis entrenamientos deportivos
programas para registros de entrenamientos
Hoy en día hay multitud de aplicaciones con las que poder seguir un registro de entrenamientos. Depende bastante de la marca de reloj que se use para ellos, las más conocidas pueden ser Garmin Connect y Strava, pero existen para Coros, Huawei, Xiaomi y más.
Todas ellas aparte del tiempo, distancia, aportan muchos más datos, como pulso, cadencia, potencia y luego marcadores "propios de la marca" o los que estén de moda ahora según estudiosos del esfuerzo y mejora física.
Si cambias de reloj, o te gusta más otra plataforma, llevarte todos tus datos no es tan facil y tan siquiera es posible. Datos como las zapatillas de correr u otro equipo utilizado, reloj, bicicleta, clima, sensaciones de esfuerzo, nombre del entrenamiento, notas y comentarios se pierden cuando exportas de una plataforma para importar a otra.
Hay varios tipos de ficheros a elegir cuando se exportan los datos. No voy a comentar de forma pormenoriza cada uno de ellos pero se pueden resumir en:
- Gpx, xml datos de gps
- tcx, xml gps y pulso
- .fit, binario, el más completo pero se pierden los datos que comenté anteriormente por considerarlos metadatos. Se necesita visor especial o programa para visualizar este fichero.
Otra opción es pedir que te de todos los datos que tienen sobre tí (aplicando GDPR), un take away de la cuenta. Obtendrás cientos de ficheros de distintos formatos que son muy dificil de enlazar.
Ninguna plataforma me convence al completo. Los datos o facilidad de uso que tiene alguna, no las tiene otra.
Datos como saber de forma rápida cuántas sesiones de ejercicio he hecho en un año determinado, horas, kilómetros, no se obtienen de forma clara en todas.
Añado además que para cada plataforma las funcionalidades que tiene la app en el móvil no son las mismas que las que tienen via web delante de un ordenador. En Garmin Connect de la web no puedes ver o hacer lo mismo que en la app del móvil.
mi sistema de registro de entrenamientos
Desde 1994 tengo registrados todos mis entrenamientos deportivos. Sí. Así de maniático llevo años. Cada vez utilizaba una forma distinta, al principio con un programa que me hice en C, pero la mayor parte del tiempo he acabado con un excel.
Ese excel es la "fuente". Luego, exportando esos datos a csv, genero mediante varios scripts gráficos y datos que puedo ver cuando quiera en una página web privada. Ese es el resumen: excel, csv, scripts, gráficos y tablas, web.
Tengo los datos que realmente me interesan como historial deportivo, de más de 32 años, sin perder ni uno solo de ellos. Unos 3.500 registros al dia de hoy.
Comento.
columnas del excel
Estos son los datos que relleno de forma semiautomática (luego detallaré la forma). Algunas celdas se autocalculan como el día de la semana o el ritmo. Las columnas como Descripción, donde anoto todo lo que quiera, Clima, Intensidad, Sensaciones son las que no merece la pena ligarlas con los datos que tuviera cualquier aplicación, son los "metadados".

En total 27 campos variados, por ejemplo si es competición, el tiempo del ganador para sacar porcentajes de estado, desnivel, horas de sueño, enlace a Strava.
proceso de actualización del excel
Después de un entrenamiento, al finalizar en el reloj, se sincroniza con la app del movil. Tengo habilitado mi reloj actual, Coros, para que suba también a Strava. Además también con https://intervals.icu, para mi la mejor plataforma para quien quiera hacer estudios más avanzados.
Al llegar a casa y sentarme delante de un ordenador, abro el terminal y ejecuto un script (lo tengo en el alias "icu") hecho por mí, que descarga de intervals.icu los registros que todavía no tengo en el excel. No se descarga todos, solo los nuevos entrenos.
Se descarga los datos que me interesan y en el mismo orden que tengo que rellena el excel de forma que copio el resultado y pego en el excel, no tengo que teclear el tiempo, distancia, datos de pulso medio, máximo y recuperación, zapatillas, hora de entrenamiento, peso, link a la actividad de Strava, desnivel, etc ..
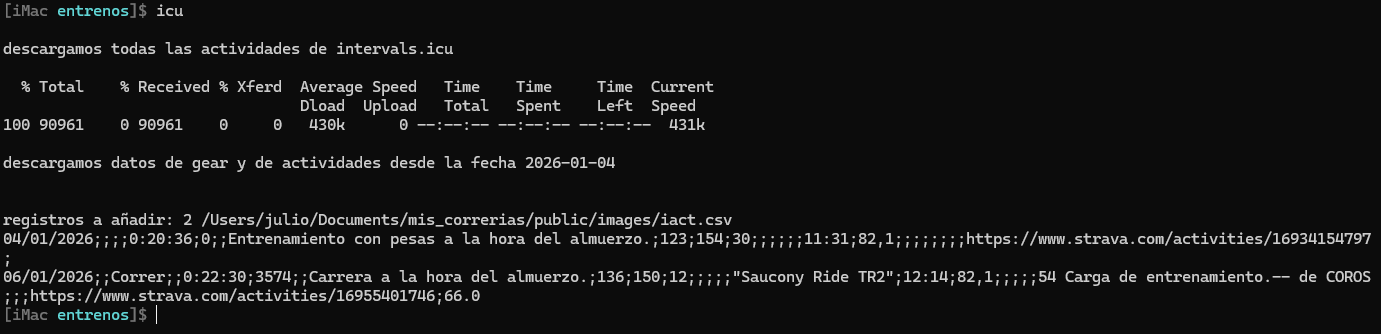 Luego en el excel, le cambio el título, escribo la descripción/notas, clima, sensaciones y grabo.
Luego en el excel, le cambio el título, escribo la descripción/notas, clima, sensaciones y grabo.
Así tengo unos 3.500 registros de entrenos desde 1994 hasta hoy. Esta es la fuente. Ya pueden avanzar los relojes y sus web, y yo cambiar de marca de relojes, que yo sigo teniendo los datos principales.
gráficos y tablas resumen a web privada
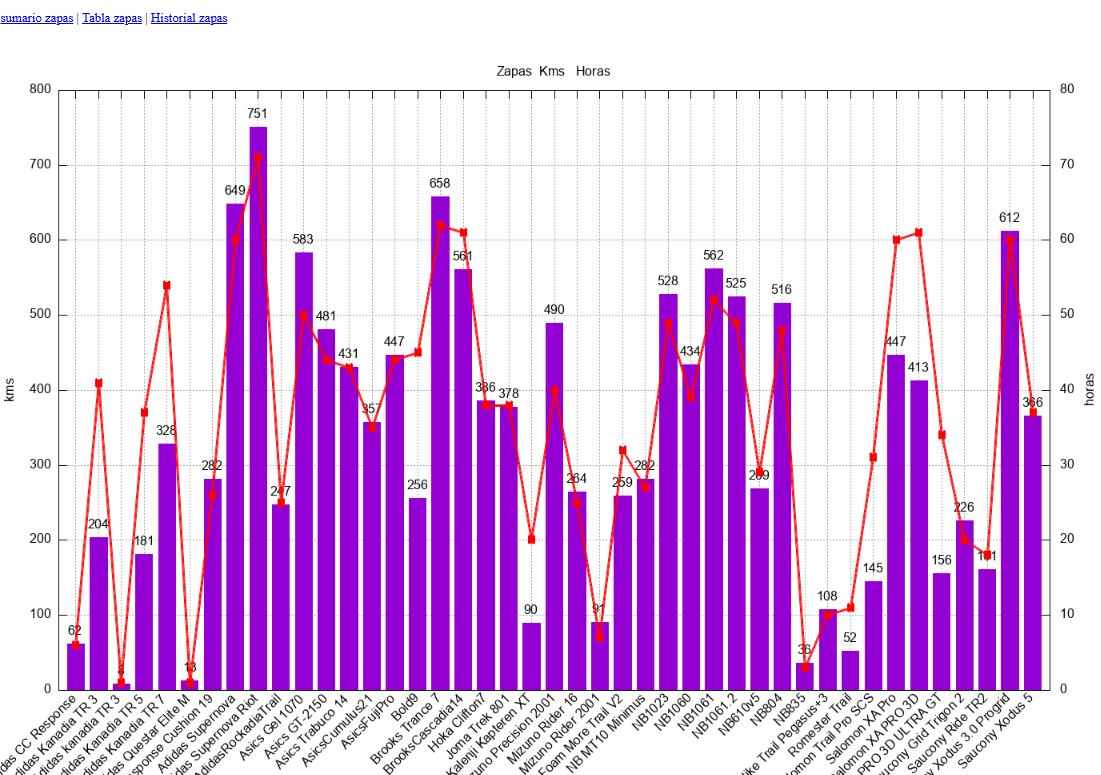
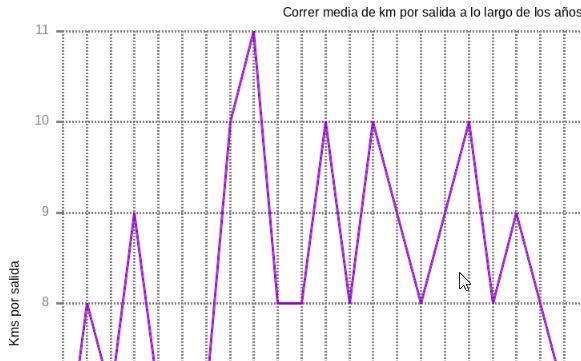
Ahora viene el sacar lo que me ha interesado del resumen de estos. Datos. El excel se convierte en csv y con otro script/alias "entrenos" llama a su vez a otros cuantos scripts en bash (por tenerlos separados según la función de cada uno) y con herramientas como gnuplot me grafican kms, sesiones, horas, ritmo, a lo largo de años o el periodo que quiera. Punto aparte también para los kms hechos con cada zapatilla.
Estos otros cuantos gráficos y tablas tsv obtenidos suben mediante git a una página web privada que tengo, para poder verlos de forma muy visual desde cualquier parte, no necesito el excel para consultar.
mostrando los resultados en la web privada
Pongo aquí algunos ejemplos de lo visto anteriormente. De momento la página es privada pues puede haber datos personales en la notas de los entrenos.
Strava. Página de postureo total donde damos nuestros datos de pulso y ejercicio gratis o pagando "¿y mantienes la página privada?". Además de postureo la verdad es que Strava puede motivar a salir más a hacer ejercicio al ver cómo tus compañeros lo hacen.
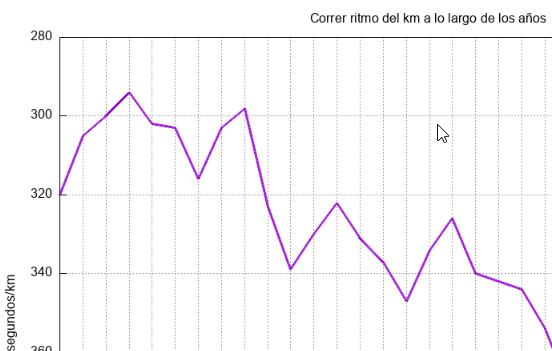
Es una página web muy simple. Tengo en la cabecera un link por cada deporte que hice o hago, y otra "Todo" agrupando todos los deportes. Cada deporte tiene como mínimo gráficos de kms, sesiones y horas por años pero sin duda la más completa es la de Correr
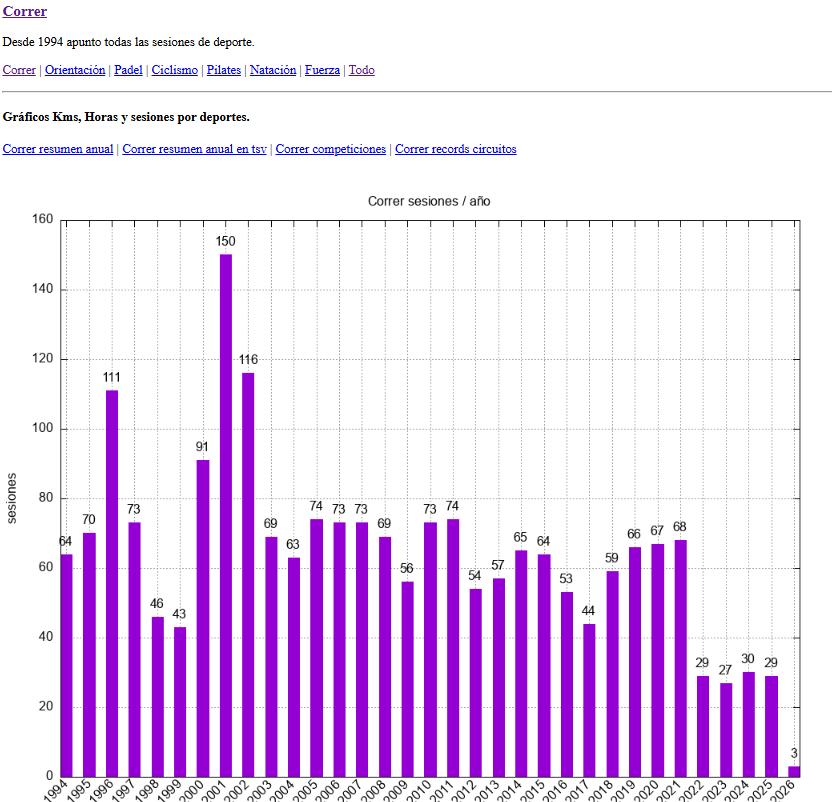
Como este gráfico hay estos otros y sus correspondientes ficheros de texto que están linkados


kms por zapatillas
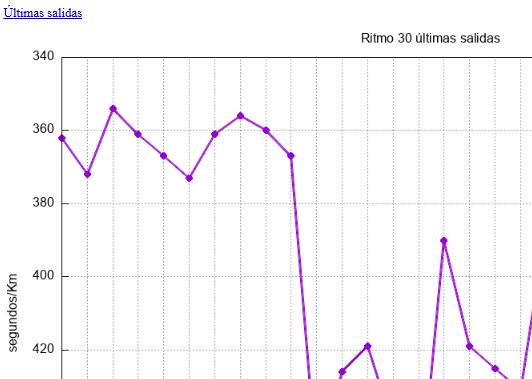
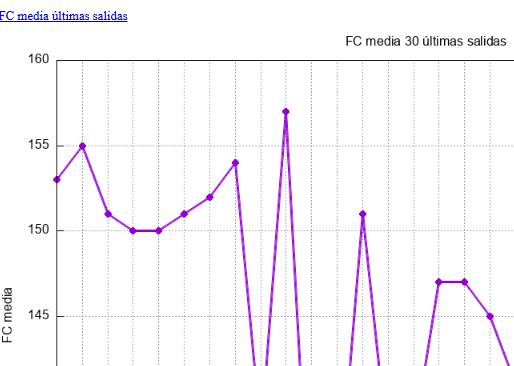
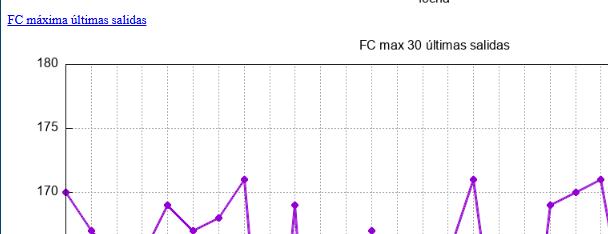
circuitos
Normalmente acabamos entrenando por los mismos sitios realizando los mismos recorridos. Por eso es bueno registrarlos para saber si hay mejora o no. También se grafian y los links que aparecen antes de la imagen llevan a unos ficheros de texto que indican las veces que se ha corrido ese circuito, distancia y tiempos mínimos y máximos, mejor y peor tiempo sus fechas y sus comentarios.
Todo esto claro es un dato/fichero más que se genera en cada actualización del excel.

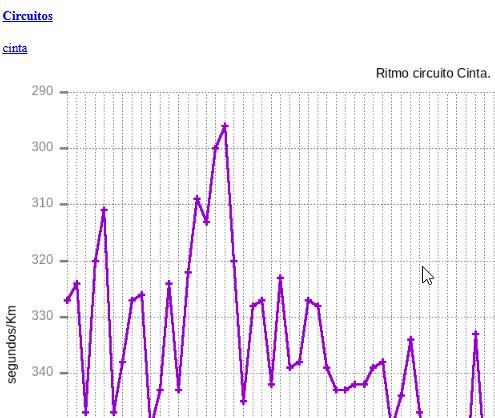
y así por cada circuito que es reseñable por haberlo hecho varias veces.
la pestaña todos los deportes
Acumulado de todas las variables sin detallar tipo de deporte.
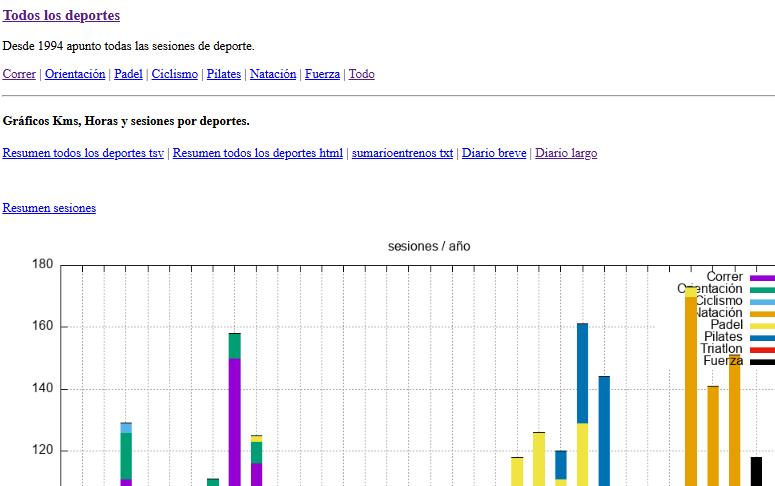
Además hay links para ver los records, los tiempos de las competiciones, y diario breve y largo del excel en sí pero en formato html.
deporte de Orientación
Mención especial a este deporte que tanto me gusta. Aparte de todo lo anterior, genero más información para cada competición en la que participo de este deporte.
https://blog.julb.es/mapa-marcando-los-lugares-que-hice-carreras-de-orientacion.html Es una página de Google que muestra en un mapa todos los sitios donde he hecho orientación. Además pinchando en cada icono me muestra datos de esa carrera, sacados todos del excel.
El script genera también un fichero en markdown, para utilizar en Obsidian, que me muestra de forma bonita los datos de este tipo de entrenos del excel. ¿por qué? porque mi memoria es ya "lenta". Es decir, de primeras no me acuerdo si estuve en tal población o no, si he corrido allí o no, necesito tiempo o algo que haga recordar. Es por eso que tengo unos 400 ficheros de markdown donde ver dónde he hecho carreras de orientación, apuntado en el campo "notas", de forma rápida en el móvil.
resumen
Del reloj a la app del movil. De https://intervals.icu descarga mediante "icu" para actualizar el excel. Del excel generar con script "entrenos" resúmenes y subida a web
Puede parecer complicado y lo es. Pero no tardo ni 1 minuto en actualizar un entreno y tener todo como quiero y no veo forma ahora de simplificar conservando todo sin amarrarme de por vida a una app comercial que no me cumpla todos mis requisitos.
Tags: awk, bash, gnuplot, python, web
De calendarios ics a fichero de texto
Se trata de hacer un script en bash/awk que dados varios calendarios en formato ics genere un fichero de texto muy similar a esta estructura
https://terokarvinen.com/2021/calendar-txt/
En un principio hice el script para que simplemente cogiera fecha y asunto del .ics. Eran pocas lineas.
Pero siempre se quiere mejorar por lo que lo adapté para:
- poder tratar masivamente y de una vez más de un .ics y con todos ellos generar un único fichero de texto.
- para una misma fecha puede haber más de un evento, en el fichero de texto tiene que ir todo en una línea
- calendario de cumpleaños:
- que ponga en el asunto los años que cumple
- cuidado cuando no se sabe el año pero sí el dia y el mes
- eventos con frecuencia, solo cojo los anuales. Genero además ya el registro para el año que viene.
- rellenar en el fichero los días que no tienen eventos, con su dia de la semana.
Todo esto derivó en un script con unas cuantas funciones y más de 150 líneas.
Más complicado fue dónde guardar este fichero resultante, dónde poner la tarea programada en macos (vaya suplicio comparado con un simple "crontab -e" del linux), cómo actualizar de forma rápida los cambios y por último el método de obtener de varias formas el fichero txt resultante.
El resultado está bien pues además me creé un alias "h" para que me listara en pantalla los x dias más cercanos con sus eventos a partir de la fecha del día.
¿no es más fácil coger el móvil y abrir la app del calendario? sí. Pero si estás trabajando en el ordenador y con un terminal abierto, teclear "h" es más rápido que incluso con el ratón pinchar en el icono.

Diferencias entre 2 organigramas
Tenemos un organigrama que se publica en formato pdf. Cada vez que hay cambios publican una nuevo pero no avisan de ello y tampoco se informa de cuáles han sido. Por lo que si quieres saber los cambios de organigrama es muy dificil pues el pdf tiene varias páginas.
Tiene esta pinta. El nombre del empleado y su cargo a veces viene arriba junto a un grupo de más personas, otras veces el cargo viene abajo. Si hay nuevos puestos creados se pueden mover las ramas de los árboles por lo que no siempre figuran todas las dependencias en el mismo orden.
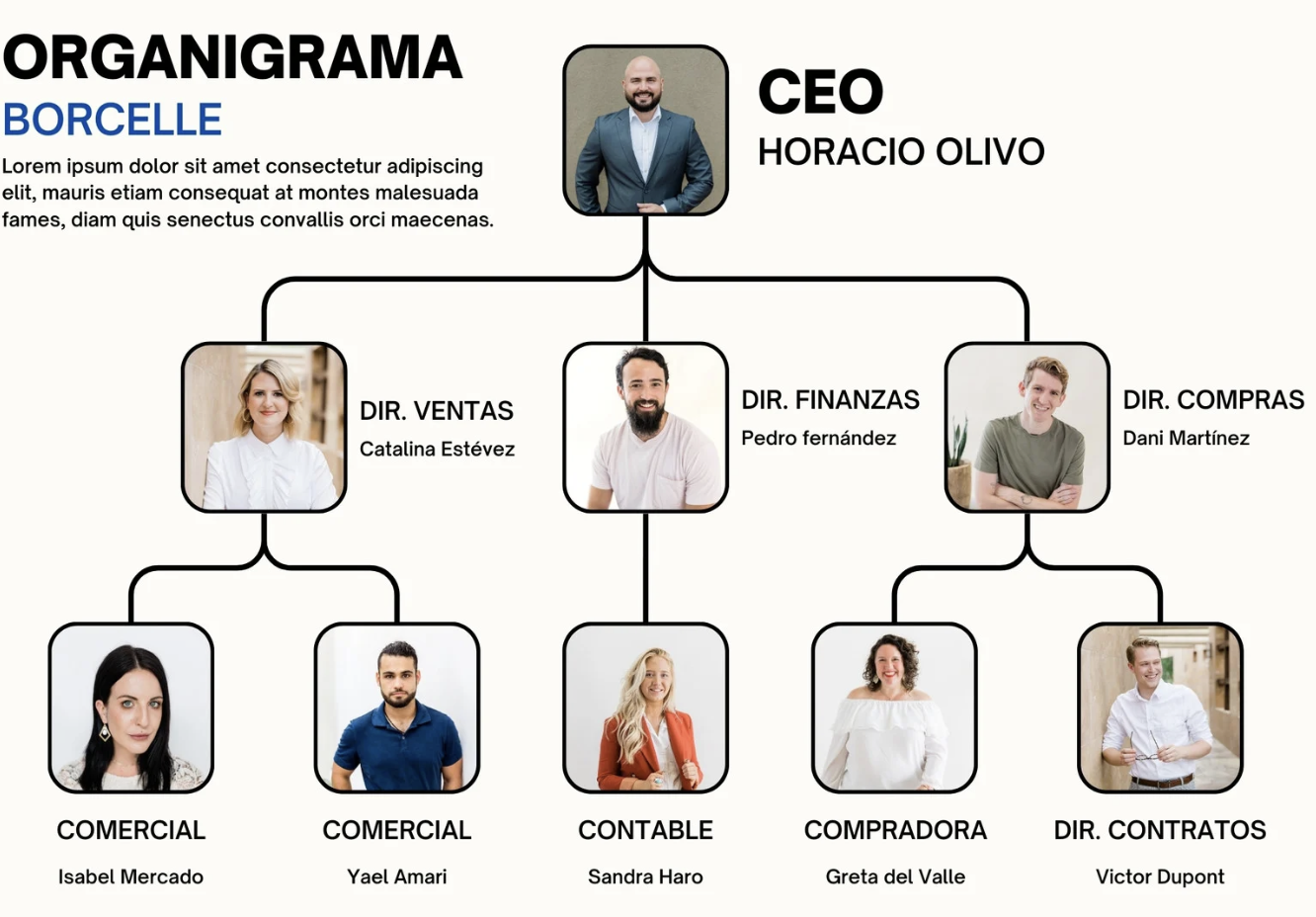
ejemplo imagen canvas
La intención es crear un primer script que te diga los nombres que ya no están en el nuevo organigrama y sí que estaban en el anterior, y al revés, las nuevas incorporaciones.
El script de momento no contempla cambios de funciones de un empleado que estaba en los 2 organigramas. Y también puede cometer otros errores que más tarde comentaré.
Con bash, awk y herramientas gnu como pdttotext podemos implementar el script.

Obteniendo un resultado parecido a este:
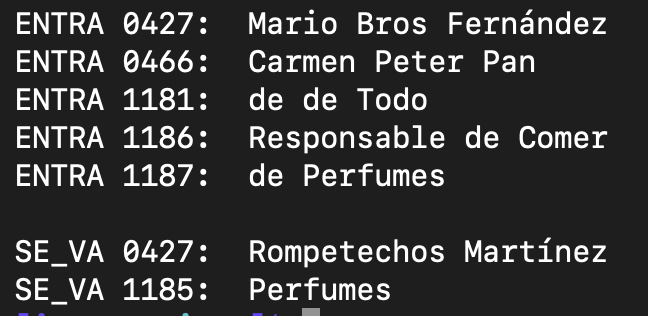
También con diff muestra las diferencias de forma más críptica pero que nos serviría para corroborar un poco.
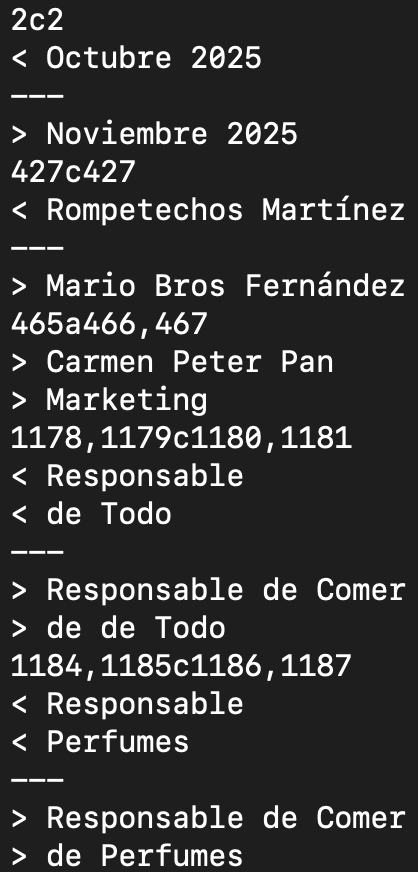
Como se ve el script tiene muchas pegas, como nombres repetidos, cambios de función y más, pero para un primer ataque para ver los cambios, y con 4 lineas de script, me vale.
Seguro que le subo los 2 ficheros a la IA y me dice las diferencias. Pero no me apetece. Prefería divertirme.
EasyVista, diversos scripts
Ahora todos los scripts que tenía para Redmine, por cambio de herramienta, los tengo que adaptar a EasyVista.
Pereza total. Solo adaptaré los más necesarios y según los vaya necesitando. Tiempo.
Básicamente sigue siendo lo mismo. Bajarse los datos con curl y esta vez utilizar jq para estructurar los json y resto que haga falta con awk.
Sigo intentando no poner código completo.

Buscarv con bash y awk
Me pasan más de 60 ficheros excel para que les inserte el código postal en una columna nueva al lado de la columna nombre.
En total son aproximadamente cerca del millón de registros y ocupan unos 90MB.
De nuestra mano obtener el fichero con la correspondencia de cada nombre y su código postal, eso es otra historia, pero vamos a suponer que lo tenemos.
No me apetece nada abrir cada fichero, insertar columna, hacer =BUSCARV con el fichero de postales abierto, extender fórmula a toda la columna, copiar columna, pegar solo valores para que no tenga enlace y guardar. Así para los sesenta ficheros. Obvio también aquí la gestión de errores por los no encontrados.
Vamos a hacerlo con herramientas gnu, bash y awk.
Cada fichero tiene esta pinta

Y el de códigos postales esta otra

Nos instalamos herramienta xlsx2csv que convierte un excel en fichero texto y empezamos con nuestro script.
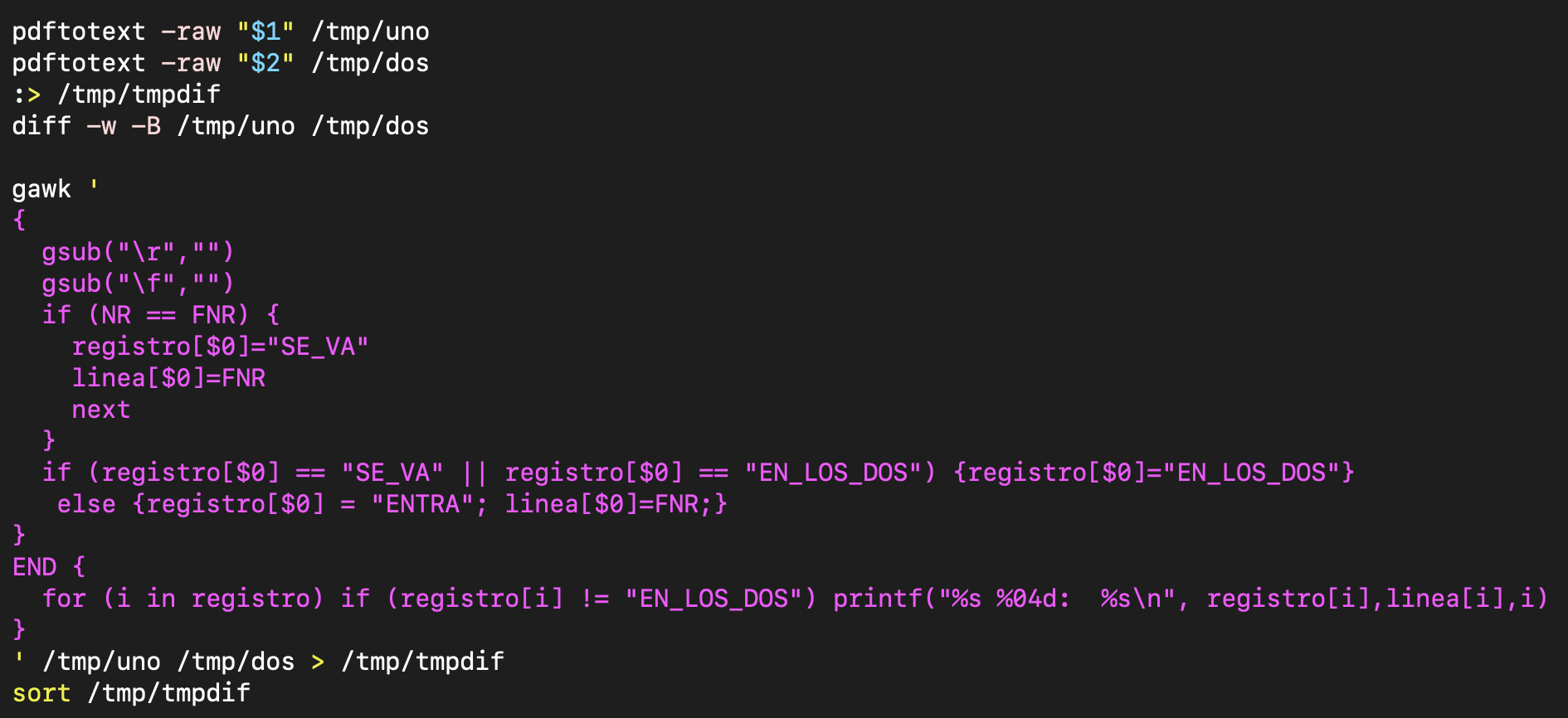
El bucle principal sería este que llama a la función postal:
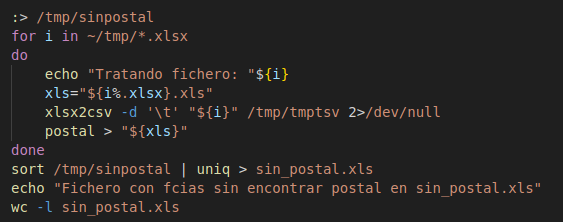
Se trata de recorrer todos los xlsx de la carpeta, y por cada uno de ellos convertirlos a texto con separador tabulador, localizar por nombre su código postal (buscarv) y generar un fichero con el mismo nombre que el original xlsx pero con la extensión xls para que lo pueda abrir también el excel directamente.
Además por cada código postal no localizado por nombre lo añadimos a una lista "sin_postal.xls" para tenerlos registrados.
Y la función postal sería esta:
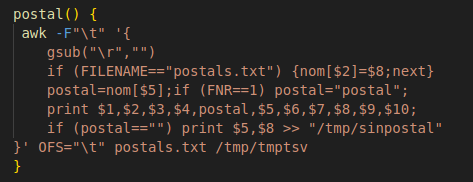
la función awk lee 2 ficheros, el primero el de códigos postales para con el segundo localizar por nombre el que le corresponde. La salida se está guardando en el fichero que queremos entregar.
Y eso es todo y el resultado

Comentar que lo que tarda este script por supuesto depende del ordenador en que se ejecute pero en el mio ha tratado esa cantidad de ficheros y miles de registros en poco más de 1 minuto.
PD: lo de generar ficheros sin códigos identificadores únicos para cada item, en nuestro caso para los compradores, es de delito. Los nombres se pueden corregir a lo largo del tiempo, como cambiar "Mª" por "MARIA", o "MARIA" por "MARÍA" o "GARCIA,LUIS" por "GARCIA, LUIS" que provocan que el buscarv no lo encuentre luego.
Ahorrando tiempo de excel con bash awk
Tarea repetitiva con excel
Debido a un proceso de unificación de bases de datos, me pedían varias veces un excel resultante de la combinación de varios excel.
Si veo que esto será un proceso habitual y necesario a lo largo del tiempo, no me complico y prefiero hacer un programa que me lo genere directamente, pero como no es el caso pues será para unas pocas veces prefiero combinar los datos que ya tengo a un fichero.
Los ficheros excel de los que partía tienen varias columnas, más de 80, y el usuario que pedía el informe quería sólo unas columnas y en un orden específico. Ambas excel contenían en total varios miles de registros (>100K) por lo que siempre tocaba hacer:
- abrir los dos excel
- eliminar las columnas innecesarias
- insertar columnas nuevas para por ejemplo sumas de otras (ventas, stock ..)
- utilizar el BUSCARV para enlazar datos de una excel con la otra
- reordenar las columnas con lo orden que se nos pide (cortar/insertar columna).
Bien, al final con la práctica y dependiendo de la memoria del pc que se utilice, todo eso lleva unos minutos.
Pero el Excel/Libreoffice cada vez que mueve columnas con fórmulas, si se tiene el cálculo automático activado, sufre de pausas de tiempo que molestan mucho. Lo mismo como hayas añadido tablas dinámicas.
Y menos mal que esta vez NO hacemos filtros de datos ni tampoco ordenamos, porque eso multiplica el tiempo de pausas en cada operación de cortar-insertar-filtrar-ordenar del Excel.
Ahorrando tiempo con awk
Me fastidia hacer siempre lo mismo pudiendo emplear el tiempo para otras cosas, además de que en las tareas repetitivas manuales es más fácil equivocarse y que te toque deshacer para volver a empezar.
Así que decido hacer un script en bash utilizando awk que me lea los dos ficheros csv y me genere un resultante con todo lo pedido. ¡no tarda más de 2 segundos de reloj! también dependiendo de la máquina.
Este es el script. Los ficheros csv iniciales son bv.csv y bz.csv de unos 21Mb cada uno.
#!/usr/bin/env bash
#cp /media/julio/vbbdd/datos_valladolid/ARTICULOS_Valladolid.csv bv.csv
#cp /media/julio/vbbdd/datos_zamora/ARTICULOS_Zamora.csv bz.csv
#
awk -F';' '
NR==FNR {
zstock[$1]=$8;
zventas[$1]=$85;
zmcam[$1]=$86;
next;
}
{
gsub("\r","");
vventas=$85;
vstock=$8;
vmcam=$86;
cventas=vventas+zventas[$1];
cstock=vstock+zstock[$1];
cmcam=vmcam+zmcam[$1];
cggc=" ";
encargo=" ";
if ($1 == "CODIGO") {
cventas="COOP_VENTAS_2019";
cstock="COOP_STOCK";
cmcam="COOP_UNIDADES_PDTES_PROVEEDOR";
cggc="CODGGC";
encargo="ENCARGO";
}
print $1,cggc,$6,$2,$40,$38,$39,$22,$20,$21,$30,$26,$41,$54,$55,$56,$57,$35,$3,cstock,cventas,cmcam,$5,encargo,$4
} ' OFS='\t' bz.csv bv.csv > bbdd_arts.csv

Dije 2 segundos y no llega ni a uno.
Lee primero un fichero separado por ";" donde recogemos los datos que necesitaremos consolidar, luego con el segundo fichero que lee va componiendo las columnas con las sumas, se crea la cabecera de texto con las columnas nuevas, y por fin guardamos todo un fichero separado por tabuladores listo para leer por el destinatario en su Excel.
Hay que tener en cuenta, repito, que no ordenamos ni tampoco hacemos filtros de datos. Si fuera así, el trabajo en Excel sería todavía más tedioso y en cambio con bash serían un par de palabras más añadidas al script.
Ver la cabecera y número de columna de un fichero csv
El inconveniente que se podría decir es que es laborioso con awk saber el número de campo que queremos imprimir, pues nos toca contar el orden de los campos para saber por ejemplo que la columna "ALTO" corresponde con el número de campo $54 del csv.
Para ello se tiene otra función que se carga automáticamente en bash que es fieldsc y muestra los campos de un csv y su numeración de forma fácil, y tampoco es una función muy complicada:
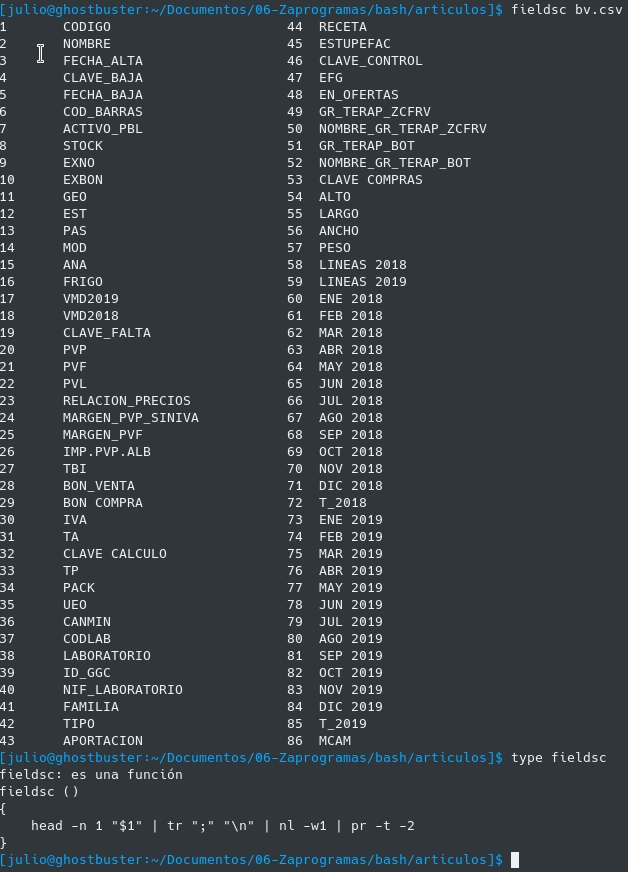
Como decía esta función y muchas otras las tengo disponibles siempre en el terminal pues se carga en el .bashrc con source bash_functions.sh.
Por cierto esta función es gentileza de Robert Mesibov ( BASHing data ) un maestro en lo que él mismo se autodenomina "data auditor and cleaning". Mucho que aprender de él en estos tiempos del Big Data.
Ampliación de registros dependiendo de que otros que ya existan de antemano
En el almacén quieren optimizar el espacio en las baldas de las estanterías y van a ampliar a 2 ubicaciones más.
A nosotros nos dicen que aquellas baldas que tenga hasta 6 posiciones dentro de ellas, que creemos la posición 7 y 8.
Nos pasan el fichero total de todas sus ubicaciones ya creadas pero no aportan ninguna regla sobre ellas.
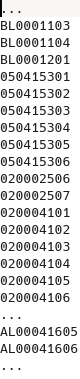
Al ver el fichero que nos dan vemos que:
- los registros tienen distinta longitud
- algunos registros ya terminan en 7, no tenemos que sugerir su creación
- no todas "las series o patrones" que pudiera deducirse que siguen los registros de ubicaciones tienen hasta posición 6
Nos piden que solo lo que termine en 6 tenemos que crear el registro 7 y 8, a no ser que exista ya.
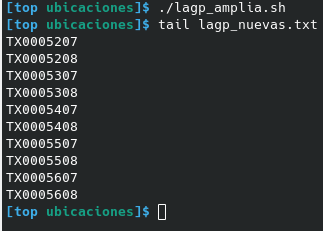
AWK una vez más con pocas líneas nos las creará:
el fichero que nos dan lo llamaremos lagp.txt lo leemos previamente para saber las que ya existen solo si termina en 6 miramos de crear la 7 y 8
```
dos2unix -q lagp.txt
awk '
FNR==NR { lagp[$1]="e"; next}
END {
for ( ubi in lagp ) {
lon=length(ubi)
if ( substr(ubi,lon-1,2) == "06" )
for ( bandeja=7; bandeja<=8; bandeja++ ) {
nue=substr(ubi,1,lon-1)bandeja
if ( lagp[nue] != "e" ) print nue
}
}
}' lagp.txt | sort > lagp_nuevas.txt
```
En 1 segundo tenemos todos las ubicaciones nuevas sea cual sea el patrón que tenga cada parte del almacén.
DHCP detectar nuevos equipos en la red con BASH
El script empezó siendo mucho más simple y solo en bash, pero al final quería que me mandase un email cada vez que encontrase un nuevo equipo, y tuve que utilizar un programa hecho por mi en Go para mandar los emails.
Además utiliza primordialmente awk que es bastante rápido en procesar ficheros de texto.
Ya lo tenía hace muchos años hecho y funcionando perfectamente en la red de mi trabajo; estaba hecho en python para redes windows. detectar-y-avisar-nuevas-concesiones-de-ip-en-nuestra-red-dhcp.html
El script busca nuevos equipos por MACs y es sabido que ya hay formas de crear nuevas macs para cada conexión así que puede haber nuevos falsos positivos por ser el mismo equipo.
Para adaptarse a uno mismo se tendría que cambiar:
- los interfaces a poner en arp-scan
- la red a buscar
- todo lo referente al envío del email
Finalmente se pone este script en el crontab para que se ejecute cada cierto tiempo y ya está.
Una vez que recibo un aviso, busco el equipo, edito el fichero dhcp.txt poniendo el nombre que quiera en la última columna y ordeno por mac (esto último porque sí).
El fichero dhcp.txt tiene esta pinta:

Solo por poner ideas.
```
#!/usr/bin/env bash
# Función: enviar email cada vez que se detecte una mac distinta conectada a la red
# Fecha creación: 29.12.2021
# Autor: Julio
# Versión: 1.0
# Detalle:
# - se necesita instalar arp-scan
# - se necesita mandaemail hecho por mi en Go
# - contiene passwd
#
now=$(date +%d/%m/%Y"_"%T)
sudo arp-scan -x -I wlp59s0 192.168.0.0/24 > wdhcp_now.txt
sudo arp-scan -x -I enp58s0f1 192.168.0.0/24 >> wdhcp_now.txt
cat wdhcp_now.txt | sort -k2,2 | uniq > dhcp_now.txt
awk -F"\t" -v now="$now" '
NR == FNR {
mac[$2]=$0;
next;
}
{
if (mac[$2] == "") {
nuevo+=1
printf("\n%s\tdispositivo nuevo: %s", nuevo, $0)
#gsub("\\:",":",rit2)
print $0"\t"now"\t?" >> "dhcp.txt"
}
}
END {
if (nuevo>0) {
printf("\nse encontraron %s nuevos\n", nuevo)
print "semaforo" > "dhcp_nuevos.txt"
}
else {
print("\ntodo ok")
}
}
' dhcp.txt dhcp_now.txt
if test -f "/tu_ruta/dhcp_nuevos.txt"
then
cadena="email_emisor|tupassword|tuservidor_smtp|tu_puerto_smtp|destinatario|Nuevos_equipos_detectados_"$now"|.|dhcp.txt|"
echo -e "\nmando email"
mandaemail "$cadena"
rm dhcp_nuevos.txt
fi
rm wdhcp_now.txt
rm dhcp_now.txt
```
Excel varias pestañas y datos dispersos en varias filas o columnas pasarlo a fichero tabulado
Me pasan fichero excel con multitud de pestañas tal que así

Dentro de cada hoja hay datos agrupados por Repartos como código cliente, nombre, población y orden
pero pueden estar en cualquier parte de la hoja excel (columna y fila), en este caso empiezan en la columna A y F

pero también pueden empezar en la columna B fila 23

Se require fichero tabulado en el cual la primera columna sea el nombre de la pestaña/hoja del excel
y el resto las columnas antes mencionadas: reparto1 o reparto2, codigocliente, población, orden
este sería un ejemplo para pestaña 174 reparto 2

En lugar de manipular todos estos datos a mano, un script utilizando herramientas disponibles en linux genera
el fichero deseado en 1 segundo:
```
#!/usr/bin/env bash
# Función: crear YVLG_KMS_ORDEN segun excel que nos pasen
# Fecha creación: 13.04.2023
# Autor: Julio Briso-Montiano
# Versión: 1.0
# Detalle:
# - correr primero xlsx2csv -s 0 -d tab EXCEL_ORDEN.xlsx > EXCEL_ORDEN.txt
# - tu responsabilidad chequear
# - si quieres excluir alguna ruta renombra la hoja del excel que sea añadiendo alguna letra p.e "x"
#
set -ueo pipefail
if [ $# -lt 1 ]
then
echo "Formato: ./kms.sh <excel.xlsx>"
exit
fi
xlsx2csv -s 0 -d tab $1 > tmpkms.tsv
awk -F"\t" '{
gsub("\r","")
if ( substr($1,1,7) == "-------" && NF == 1) {
gsub(" ","")
split($1, a, "-")
#ruta=sprintf("%06i",a[10])
ruta=substr("000000"a[10],1 + length("000000"a[10]) - 6)
}
if ( ruta*1 > 1 )
for (i=1; i <= NF; i++) {
if ( match($i," Reparto ") ) {
reparto=substr($i, RSTART+9,1)
colreparto[i]=reparto
}
if ( ($i*1 > 10000000 && $i*1 < 19999999) || $i == "CE20" ) {
if ( $i == "CE20" )
tipo="A"
else
tipo="E"
print ruta,colreparto[i],"01.01.2023","31.12.9999",$i,$(i+3),tipo,"X"
}
}
}' OFS="\t" tmpkms.tsv > tmpyvlg_kms_orden.tsv
sort -t$'\t' -k1 -k2 -nk6 tmpyvlg_kms_orden.tsv > yvlg_kms_orden.tsv
echo -e "Generado fichero yvlg_kms_orden.tsv"
```
mRemoteNG sacar passwords almacenadas
Cuando se exporta todos los datos desde el propio programa mRemoteNG sea a xml o csv, este lo hace con las claves password cifradas.
Gracias al programa en python de https://github.com/kmahyyg/mremoteng-decrypt se pueden extraer de 1 en 1.
Con este programa pasando como parámetros un fichero a mi no me ha funcionado. Sí que lo hace si se pasa con la opción "-s" "passwordciffrado".
Un ejemplo del xml exportado

Para no tener que ir utilizando varias veces lanzando el programa mremoteng-decrypt.py -s "xxefseasdf.." hice este script en awk que sacaría en este formato de pantalla el password descifrado por cada nodo que tenga el xml.
La salida sería parecida a esto:
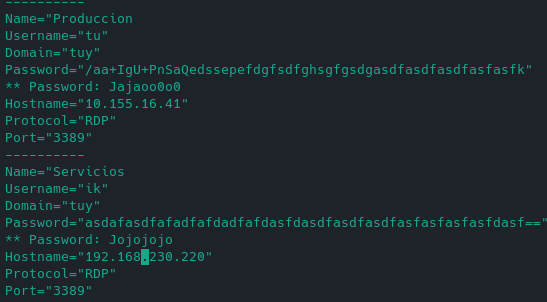
Lo modificaré para que me cree un script/fichero por cada nodo en el xml, que lance el servicio que sea según tipo conexión RDP/VNC/SSH, con el password y username. Así tendría un fichero/script por cada conexión sin tener que tener que importar datos a otro programa tipo Reminna.
```
awk '{
for (i=0;i<=NF;i++) {
if ($i ~ /^Name|^Node\ Name=|^Username=|^Domain=|^Password=|^Hostname=|^Protocol=|^Port=/) {
if ($i ~/^Name/) print "----------"
print $i
if ($i ~ /^Password=/) {
split($i,p,"\"");
pass="";
if (length(p[2]) > 2) {
"python mremoteng_decrypt.py -s "p[2] | getline pass;
print "** "pass;
}
}
}
}
}' xml
```
Tags: awk
Redmine, diversos scripts III
Otro script en bash y sobre todo awk.
Es lo que mas me viene siempre a mano en cuanto se me ocurre automatizar alguna tarea, o sobre todo sacar resumen de una fuente ingente de datos.
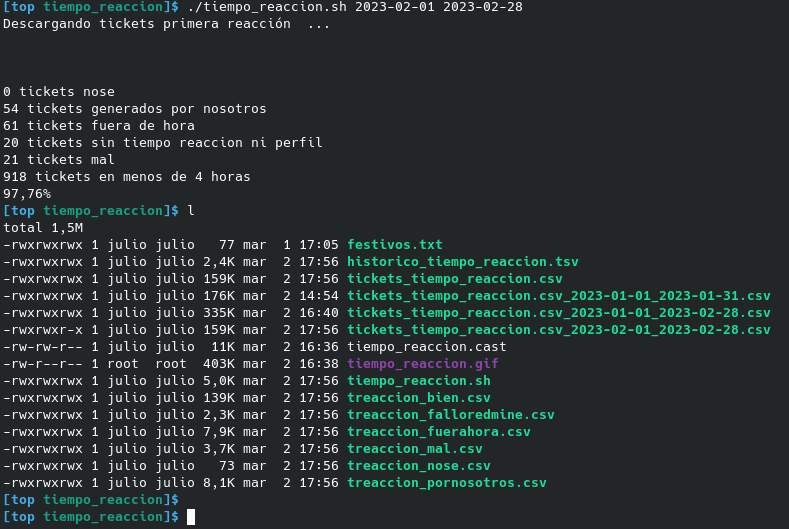
Esta vez el script tiempo_reaccion.sh exporta tickets de redmine entre las fechas que se le meta como parámetros y analiza el tiempo de respuesta en conjuntoe:
- descarga todos aquellos tickets entre fechas
- los que tengan tiempo de respuesta superior a una dada analiza que:
- si fueron dados de alta durante el finde de semana los excluye (desde el viernes por la tarde)
- si fueron dados de alta fuera jornada laboral en día de diario también los excluye
- si son tickets creados por nosotros, no contabilizan para el tiempo de respuesta
- crea por cada casuística 1 fichero csv
Como siempre mola obtener todos esos datos de forma rápida y se agradece no tener que trabajar de forma manual con el excel.
awk es una herramienta bestial, creada hace muchos años y que se maneja muy bien con cantidad de datos enorme.
Termina 2024 con varios scripts en bash
Utilizando sobre todo awk y curl
- fedicom3.sh: envía pedidos, descarga albaranes con esta versión de protocolo
- resumen_gasluz.sh, grafica (gnuplot) y saca varios ratios sobre consumos de estos tipos
- entrenos.sh, mejorado, muchos más gráficos, ratios de kms, sesiones, horas, por meses, por circuitos, por bici utilizada, zapatillas, fc, ...
- tickets.sh descarga de redmine y easyvista para diversas estadísticas
- tid2json2txt.sh, varias tiddlywikis que tengo, sap y gestión de temas en curso, se exportan a otros formatos donde pueda consultar de otras formas via web
- busca_me.sh, motor principal de búsquedas de ficheros
- hazcopia.sh, copias de seguridad con git y rclone
- calcrontab.sh y calen.sh , genera fichero texto y pdf diario del planning a seis semanas vista
- viajes.sh, genera ficheros varios para web consulta mis viajes
- libros.sh, lo mismo pero para libros
y más ...