
Buscarv con bash y awk
Me pasan más de 60 ficheros excel para que les inserte el código postal en una columna nueva al lado de la columna nombre.
En total son aproximadamente cerca del millón de registros y ocupan unos 90MB.
De nuestra mano obtener el fichero con la correspondencia de cada nombre y su código postal, eso es otra historia, pero vamos a suponer que lo tenemos.
No me apetece nada abrir cada fichero, insertar columna, hacer =BUSCARV con el fichero de postales abierto, extender fórmula a toda la columna, copiar columna, pegar solo valores para que no tenga enlace y guardar. Así para los sesenta ficheros. Obvio también aquí la gestión de errores por los no encontrados.
Vamos a hacerlo con herramientas gnu, bash y awk.
Cada fichero tiene esta pinta

Y el de códigos postales esta otra

Nos instalamos herramienta xlsx2csv que convierte un excel en fichero texto y empezamos con nuestro script.
El bucle principal sería este que llama a la función postal:
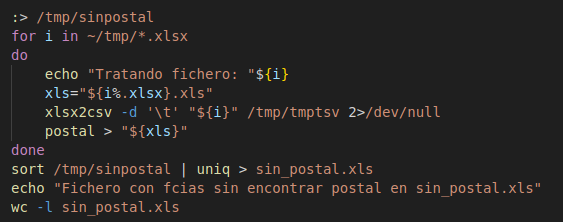
Se trata de recorrer todos los xlsx de la carpeta, y por cada uno de ellos convertirlos a texto con separador tabulador, localizar por nombre su código postal (buscarv) y generar un fichero con el mismo nombre que el original xlsx pero con la extensión xls para que lo pueda abrir también el excel directamente.
Además por cada código postal no localizado por nombre lo añadimos a una lista "sin_postal.xls" para tenerlos registrados.
Y la función postal sería esta:
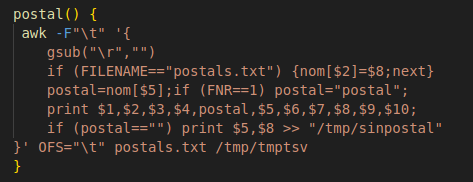
la función awk lee 2 ficheros, el primero el de códigos postales para con el segundo localizar por nombre el que le corresponde. La salida se está guardando en el fichero que queremos entregar.
Y eso es todo y el resultado

Comentar que lo que tarda este script por supuesto depende del ordenador en que se ejecute pero en el mio ha tratado esa cantidad de ficheros y miles de registros en poco más de 1 minuto.
PD: lo de generar ficheros sin códigos identificadores únicos para cada item, en nuestro caso para los compradores, es de delito. Los nombres se pueden corregir a lo largo del tiempo, como cambiar "Mª" por "MARIA", o "MARIA" por "MARÍA" o "GARCIA,LUIS" por "GARCIA, LUIS" que provocan que el buscarv no lo encuentre luego.
Excel varias pestañas y datos dispersos en varias filas o columnas pasarlo a fichero tabulado
Me pasan fichero excel con multitud de pestañas tal que así

Dentro de cada hoja hay datos agrupados por Repartos como código cliente, nombre, población y orden
pero pueden estar en cualquier parte de la hoja excel (columna y fila), en este caso empiezan en la columna A y F

pero también pueden empezar en la columna B fila 23

Se require fichero tabulado en el cual la primera columna sea el nombre de la pestaña/hoja del excel
y el resto las columnas antes mencionadas: reparto1 o reparto2, codigocliente, población, orden
este sería un ejemplo para pestaña 174 reparto 2

En lugar de manipular todos estos datos a mano, un script utilizando herramientas disponibles en linux genera
el fichero deseado en 1 segundo:
```
#!/usr/bin/env bash
# Función: crear YVLG_KMS_ORDEN segun excel que nos pasen
# Fecha creación: 13.04.2023
# Autor: Julio Briso-Montiano
# Versión: 1.0
# Detalle:
# - correr primero xlsx2csv -s 0 -d tab EXCEL_ORDEN.xlsx > EXCEL_ORDEN.txt
# - tu responsabilidad chequear
# - si quieres excluir alguna ruta renombra la hoja del excel que sea añadiendo alguna letra p.e "x"
#
set -ueo pipefail
if [ $# -lt 1 ]
then
echo "Formato: ./kms.sh <excel.xlsx>"
exit
fi
xlsx2csv -s 0 -d tab $1 > tmpkms.tsv
awk -F"\t" '{
gsub("\r","")
if ( substr($1,1,7) == "-------" && NF == 1) {
gsub(" ","")
split($1, a, "-")
#ruta=sprintf("%06i",a[10])
ruta=substr("000000"a[10],1 + length("000000"a[10]) - 6)
}
if ( ruta*1 > 1 )
for (i=1; i <= NF; i++) {
if ( match($i," Reparto ") ) {
reparto=substr($i, RSTART+9,1)
colreparto[i]=reparto
}
if ( ($i*1 > 10000000 && $i*1 < 19999999) || $i == "CE20" ) {
if ( $i == "CE20" )
tipo="A"
else
tipo="E"
print ruta,colreparto[i],"01.01.2023","31.12.9999",$i,$(i+3),tipo,"X"
}
}
}' OFS="\t" tmpkms.tsv > tmpyvlg_kms_orden.tsv
sort -t$'\t' -k1 -k2 -nk6 tmpyvlg_kms_orden.tsv > yvlg_kms_orden.tsv
echo -e "Generado fichero yvlg_kms_orden.tsv"
```
Ahorrando tiempo de excel con bash awk
Tarea repetitiva con excel
Debido a un proceso de unificación de bases de datos, me pedían varias veces un excel resultante de la combinación de varios excel.
Si veo que esto será un proceso habitual y necesario a lo largo del tiempo, no me complico y prefiero hacer un programa que me lo genere directamente, pero como no es el caso pues será para unas pocas veces prefiero combinar los datos que ya tengo a un fichero.
Los ficheros excel de los que partía tienen varias columnas, más de 80, y el usuario que pedía el informe quería sólo unas columnas y en un orden específico. Ambas excel contenían en total varios miles de registros (>100K) por lo que siempre tocaba hacer:
- abrir los dos excel
- eliminar las columnas innecesarias
- insertar columnas nuevas para por ejemplo sumas de otras (ventas, stock ..)
- utilizar el BUSCARV para enlazar datos de una excel con la otra
- reordenar las columnas con lo orden que se nos pide (cortar/insertar columna).
Bien, al final con la práctica y dependiendo de la memoria del pc que se utilice, todo eso lleva unos minutos.
Pero el Excel/Libreoffice cada vez que mueve columnas con fórmulas, si se tiene el cálculo automático activado, sufre de pausas de tiempo que molestan mucho. Lo mismo como hayas añadido tablas dinámicas.
Y menos mal que esta vez NO hacemos filtros de datos ni tampoco ordenamos, porque eso multiplica el tiempo de pausas en cada operación de cortar-insertar-filtrar-ordenar del Excel.
Ahorrando tiempo con awk
Me fastidia hacer siempre lo mismo pudiendo emplear el tiempo para otras cosas, además de que en las tareas repetitivas manuales es más fácil equivocarse y que te toque deshacer para volver a empezar.
Así que decido hacer un script en bash utilizando awk que me lea los dos ficheros csv y me genere un resultante con todo lo pedido. ¡no tarda más de 2 segundos de reloj! también dependiendo de la máquina.
Este es el script. Los ficheros csv iniciales son bv.csv y bz.csv de unos 21Mb cada uno.
#!/usr/bin/env bash
#cp /media/julio/vbbdd/datos_valladolid/ARTICULOS_Valladolid.csv bv.csv
#cp /media/julio/vbbdd/datos_zamora/ARTICULOS_Zamora.csv bz.csv
#
awk -F';' '
NR==FNR {
zstock[$1]=$8;
zventas[$1]=$85;
zmcam[$1]=$86;
next;
}
{
gsub("\r","");
vventas=$85;
vstock=$8;
vmcam=$86;
cventas=vventas+zventas[$1];
cstock=vstock+zstock[$1];
cmcam=vmcam+zmcam[$1];
cggc=" ";
encargo=" ";
if ($1 == "CODIGO") {
cventas="COOP_VENTAS_2019";
cstock="COOP_STOCK";
cmcam="COOP_UNIDADES_PDTES_PROVEEDOR";
cggc="CODGGC";
encargo="ENCARGO";
}
print $1,cggc,$6,$2,$40,$38,$39,$22,$20,$21,$30,$26,$41,$54,$55,$56,$57,$35,$3,cstock,cventas,cmcam,$5,encargo,$4
} ' OFS='\t' bz.csv bv.csv > bbdd_arts.csv

Dije 2 segundos y no llega ni a uno.
Lee primero un fichero separado por ";" donde recogemos los datos que necesitaremos consolidar, luego con el segundo fichero que lee va componiendo las columnas con las sumas, se crea la cabecera de texto con las columnas nuevas, y por fin guardamos todo un fichero separado por tabuladores listo para leer por el destinatario en su Excel.
Hay que tener en cuenta, repito, que no ordenamos ni tampoco hacemos filtros de datos. Si fuera así, el trabajo en Excel sería todavía más tedioso y en cambio con bash serían un par de palabras más añadidas al script.
Ver la cabecera y número de columna de un fichero csv
El inconveniente que se podría decir es que es laborioso con awk saber el número de campo que queremos imprimir, pues nos toca contar el orden de los campos para saber por ejemplo que la columna "ALTO" corresponde con el número de campo $54 del csv.
Para ello se tiene otra función que se carga automáticamente en bash que es fieldsc y muestra los campos de un csv y su numeración de forma fácil, y tampoco es una función muy complicada:
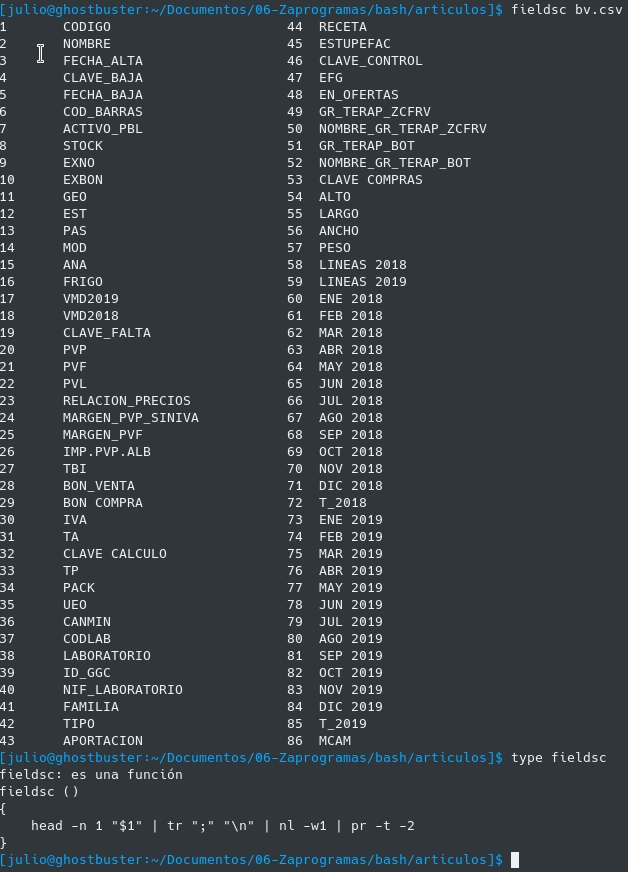
Como decía esta función y muchas otras las tengo disponibles siempre en el terminal pues se carga en el .bashrc con source bash_functions.sh.
Por cierto esta función es gentileza de Robert Mesibov ( BASHing data ) un maestro en lo que él mismo se autodenomina "data auditor and cleaning". Mucho que aprender de él en estos tiempos del Big Data.